Readyset Key Concepts
Readyset is a lightweight caching solution that turns even the most complex SQL reads into lightning fast lookups with no extra code.
Readyset slots between your application and database. It is wire-compatible with both MySQL and Postgres, so all you have to do to start using Readyset is swap out your database connection string. Readyset gives you fine-grained control over which queries are cached. Queries that aren't cached are proxied through Readyset.
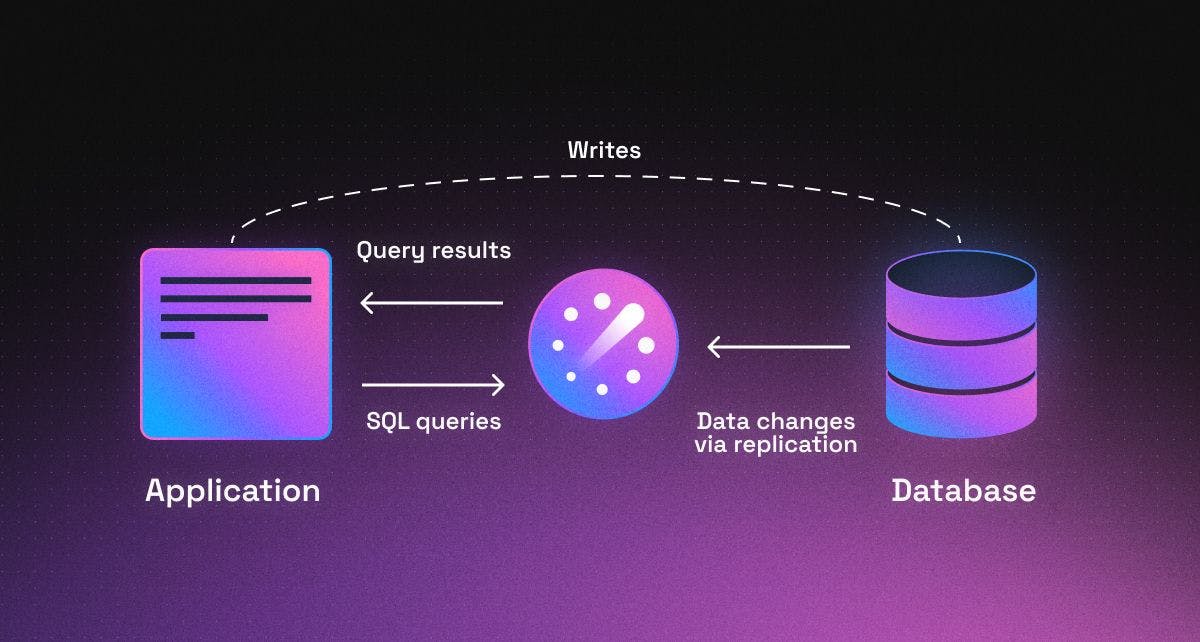
How does Readyset work under the hood?
Imagine a basic online forum application with posts, users, and upvotes. A simple database schema for this application might look like:
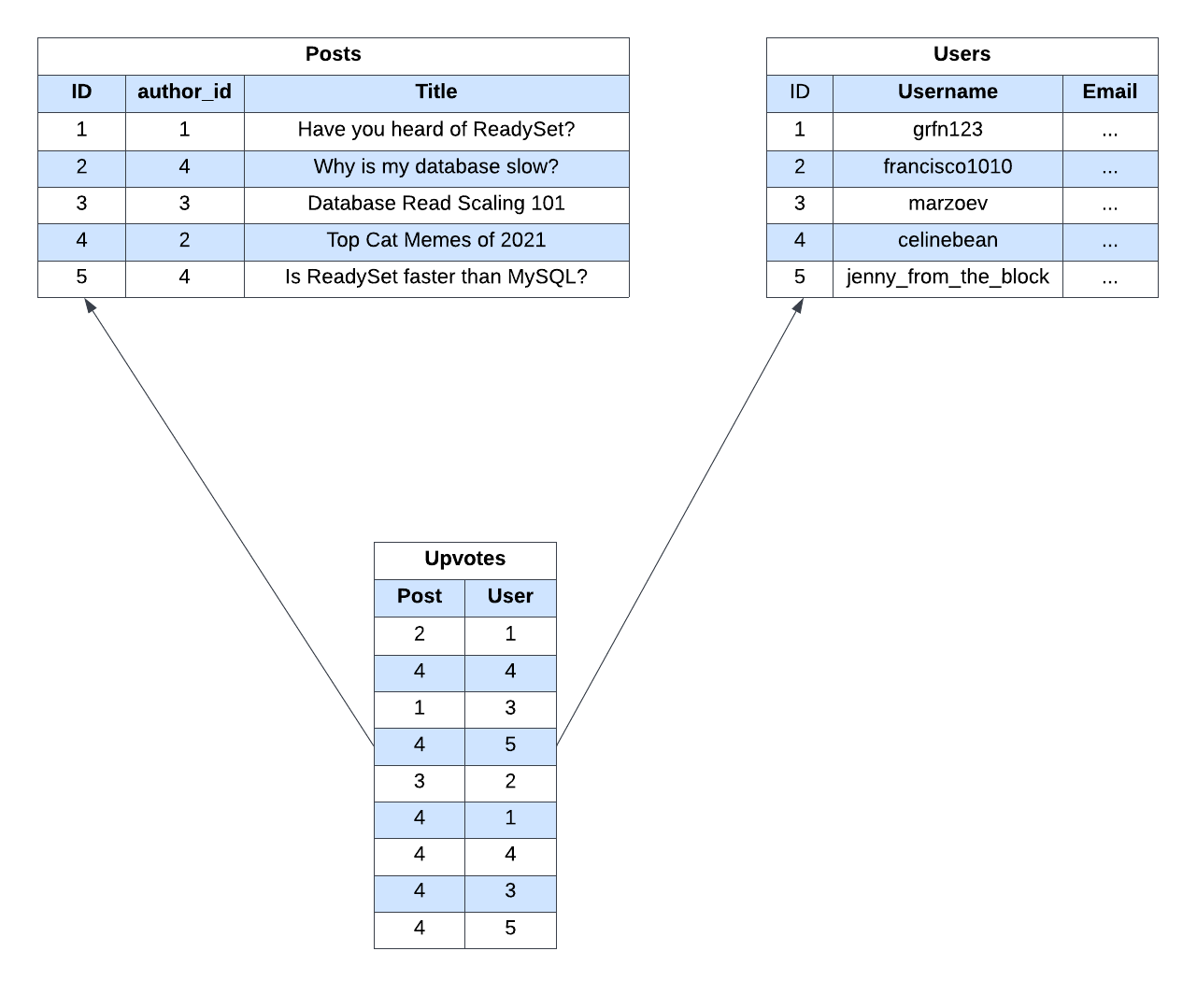
You can imagine a query like the one below, which returns all of the posts authored by a particular user:
SELECT
posts.title, posts.id, users.username
FROM
posts
INNER JOIN
users
WHERE
posts.author_id = users.id WHERE users.id = ?;Under the hood, Readyset constructs a dataflow graph for the query. Each node of the graph is updated when writes occur, keeping the query results up to date.
The graph for the query would look something like this:
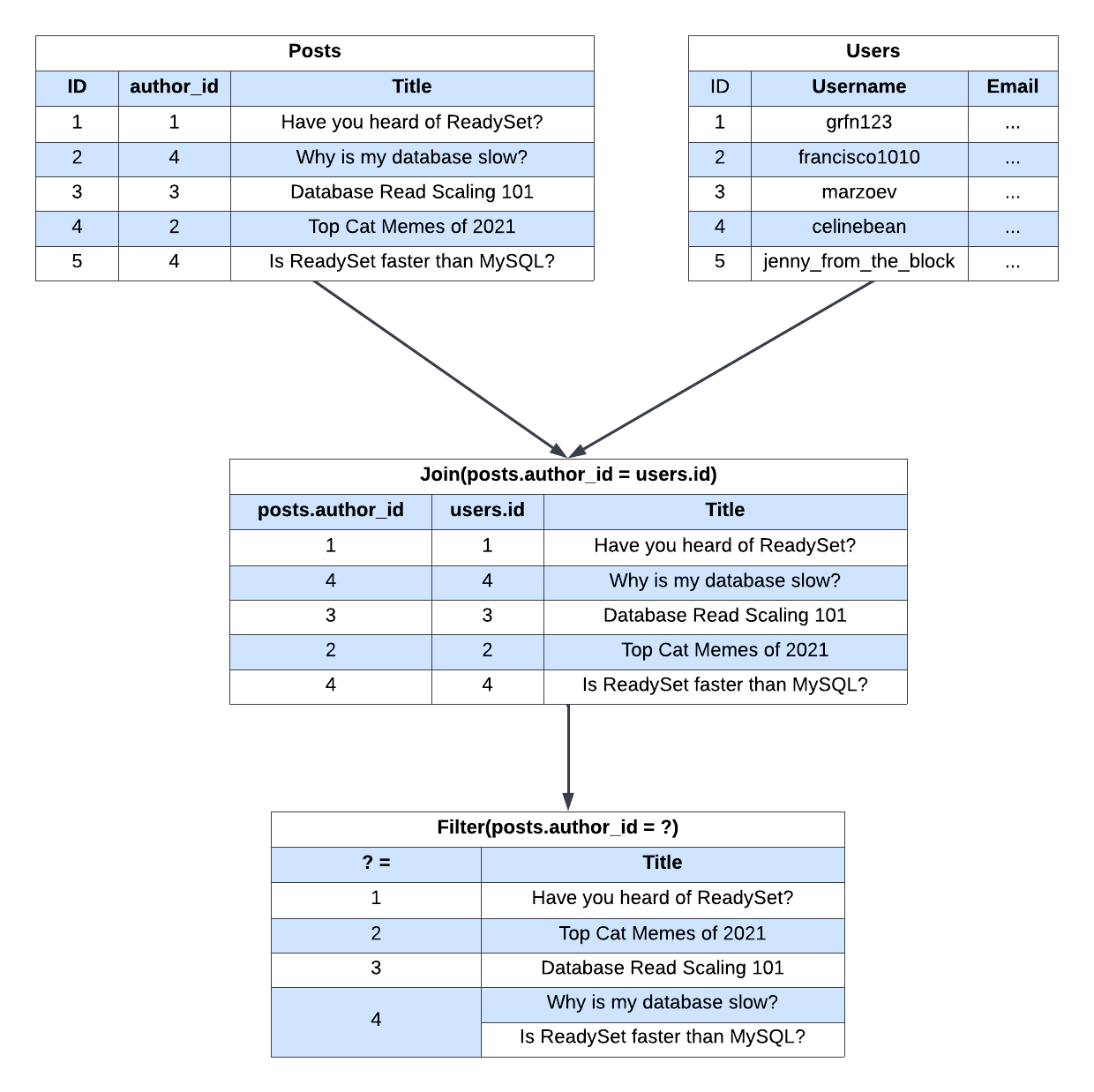
Once the graph is constructed, if a user queries all of the posts authored by user id 4, Readyset has the results ready so reads can be performed with no additional compute. Results are therefore returned instantaneously, regardless of the size of your database.
How does Readyset handle more complex queries?
One of the biggest advantages of this model is that latencies are not affected by query complexity. Let's take a look at a few more queries in this application:
Here's a point query for an article:
SELECT * FROM posts WHERE id = ?;And here's a query for the total upvote count of an article:
SELECT
id, author_id, title, vcount
FROM
posts
JOIN
(SELECT post, COUNT(*) AS vcount
FROM upvotes GROUP BY post)
AS
VoteCount
ON
VoteCount.post = posts.id WHERE posts.id = ?;In traditional database settings, as queries get more complex, performance can seriously suffer. To work around this, developers denormalize data or implement out-of-band caching solutions that require extra application logic to keep in sync with the database. With Readyset, read performance is not impacted by the size of the base tables or query complexity.
What's the catch?
Memory Overhead
There's no free lunch– Readyset trades off the cost of maintaining the dataflow graph in memory for excellent read performance. However, there are a few key ways we can mitigate this cost, such as through partial materialization. You can think of partial materialization as a demand-driven cache-filling mechanism. With it, only a subset of the query results are stored in memory based on common input parameters to the query. For example, if a query is parameterized on user IDs, then Readyset would only cache the results of that query for the active subset of users, since they are the ones issuing requests. Once Readyset surpasses a developer-specified memory limit, cache entries are evicted from memory based on a specified eviction strategy (e.g., LRU).
Readyset also makes it easy to cache only the subset of your queries that have the highest impact on read performance. You can use the Readyset dashboard to profile your existing workload and make caching decisions based on query frequency and the current latencies. If some of your queries don't need additional read performance boosts, you can continue proxying them to the customer database. As a result, they won’t take up any memory real estate in your Readyset cluster.
No Strong Consistency
Readyset is eventually consistent. There will be a small delay between when the write is issued and the cached result is updated in Readyset to reflect that write. This might not be suitable for all applications, or all parts of an application.
Is Readyset a good fit for my application?
Like most caching solutions, Readyset will have the greatest impact on read-heavy applications with non-uniform access patterns. Most web applications have a high read-to-write traffic ratio, and therefore fit the bill. Readyset generally provides immediate performance improvements in these contexts.
Can I try it?
Yes! Readyset is source-available under the BSL 1.1 license. Check out our Github (opens in a new tab) for more info.