Example: News Forum
To illustrate these concepts, we will walk through an example of using Readyset for a news forum application inspired by HackerNews.
Schema
First we define two tables to keep track of HackerNews stories and votes.
CREATE TABLE stories (id int, author text, title text, url text);
CREATE TABLE votes (user int, story_id int);
Query
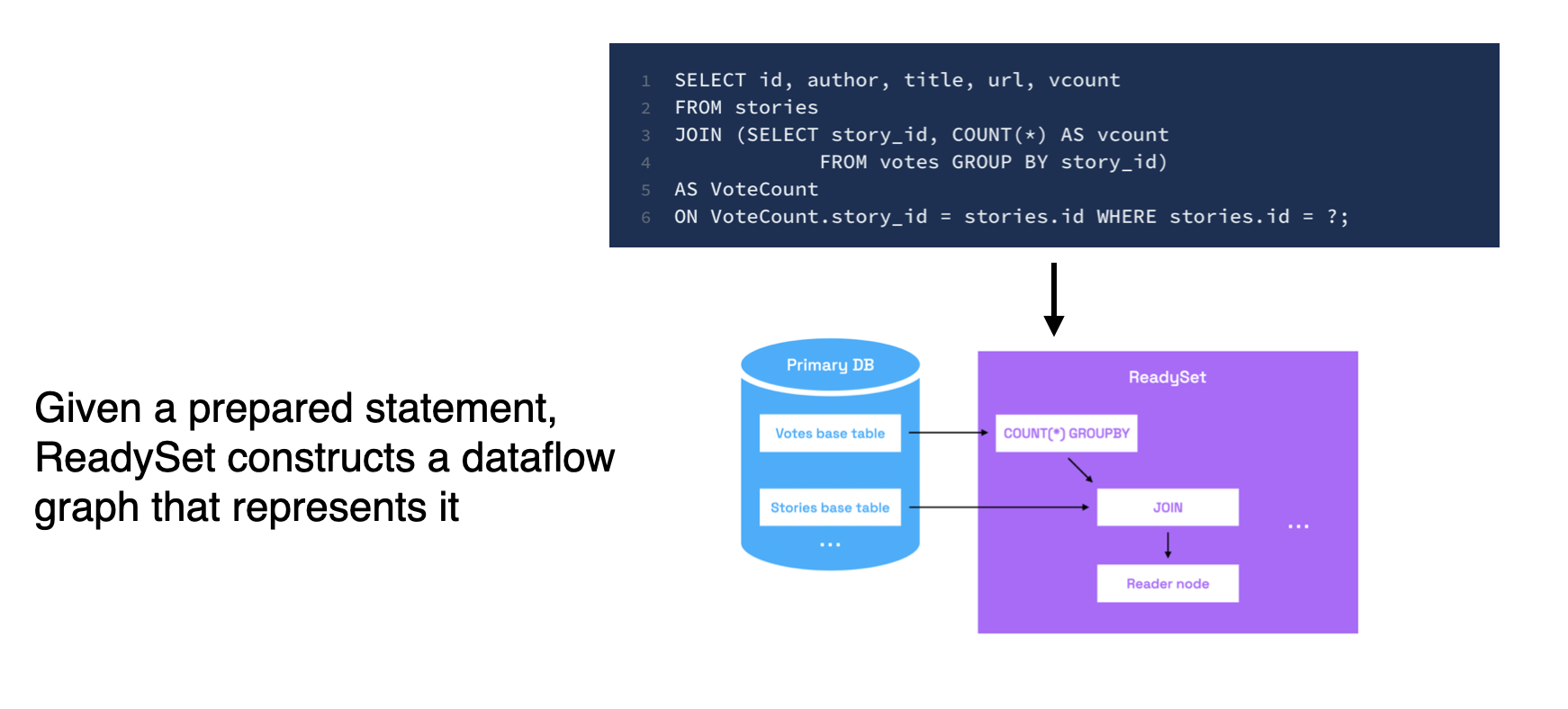
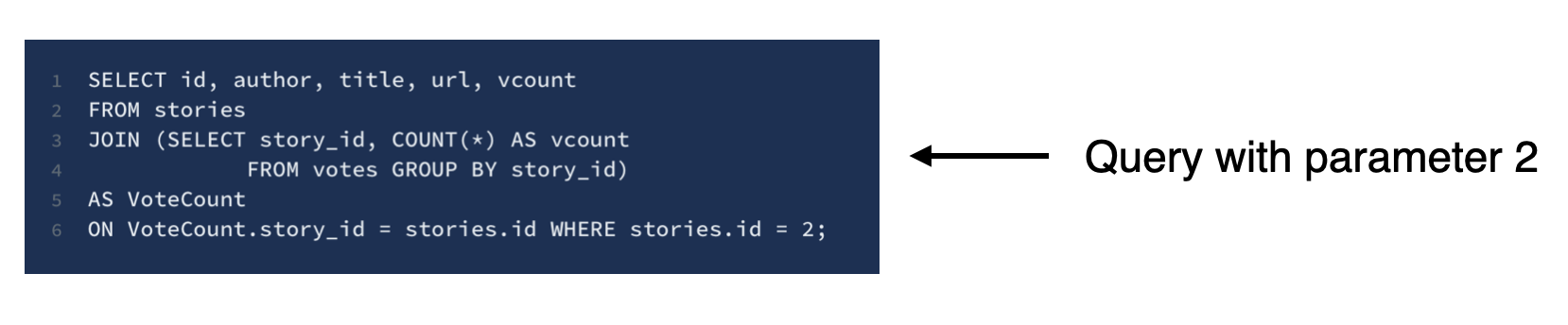
Next, we'll write a query that computes the vote count for each story and joins the vote counts with other story metadata such as the author, title, and ID.
SELECT id, author, title, url, vcount
FROM stories
JOIN (SELECT story_id, COUNT(*) AS vcount
FROM votes GROUP BY story_id)
AS VoteCount
ON VoteCount.story_id = stories.id WHERE stories.id = ?;
Caching with Readyset
Traditional databases would compute the results of this query from scratch every time it was issued. Readyset takes a different approach and instead precomputes and incrementally maintains the results of this query for commonly read keys. To accomplish this, Readyset creates a streaming dataflow graph, as described in the previous section. At a high level, the dataflow graph would look as follows:
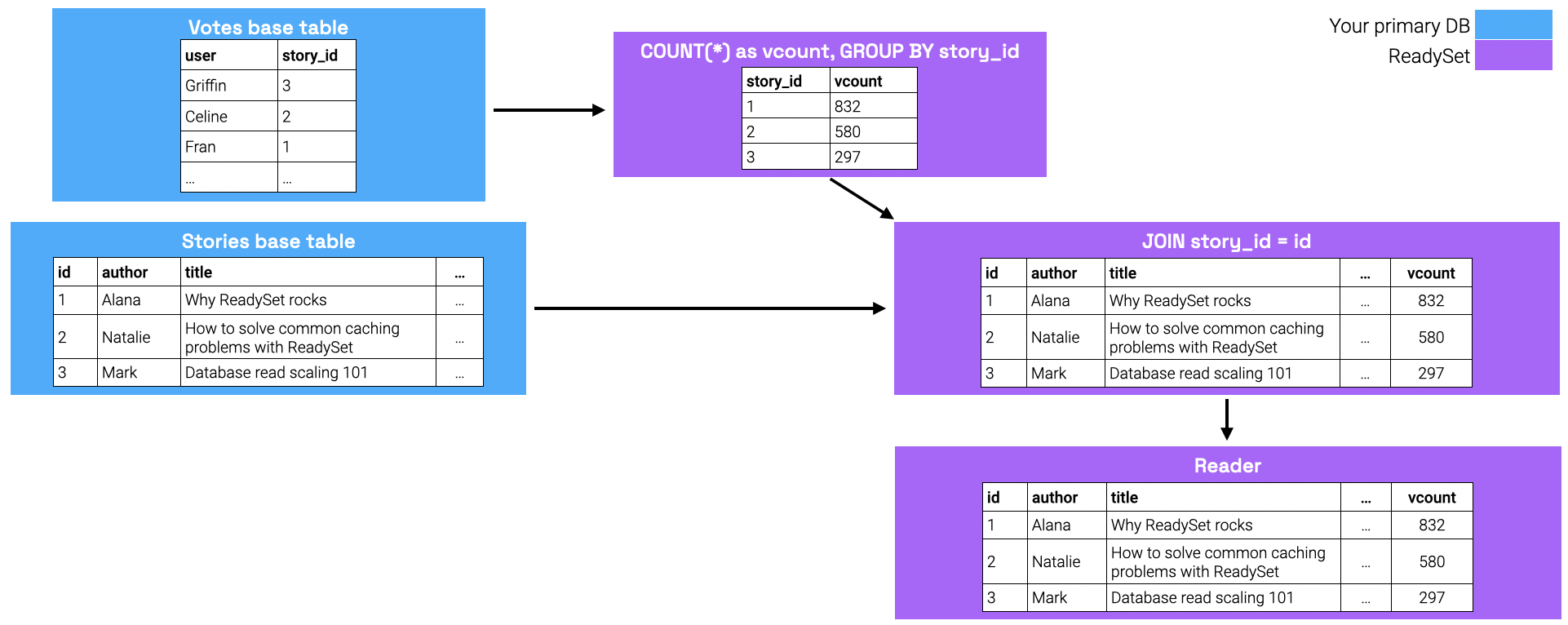
Under the hood, here's what some of the internal state might look like for this graph.
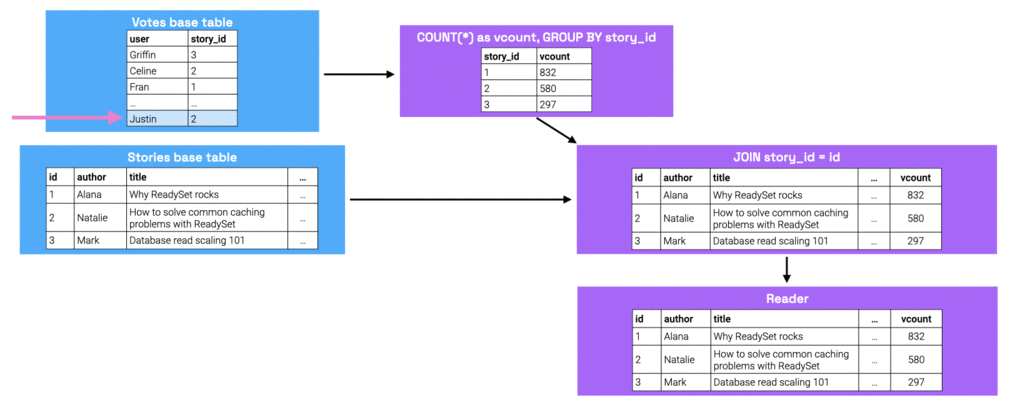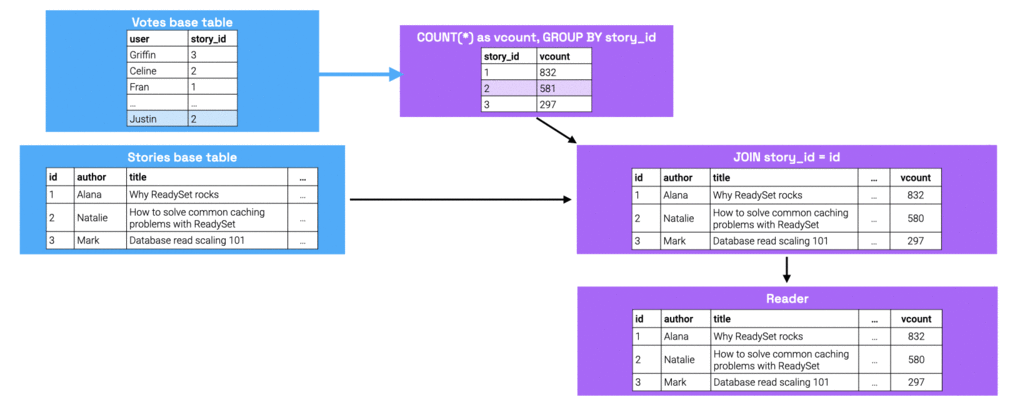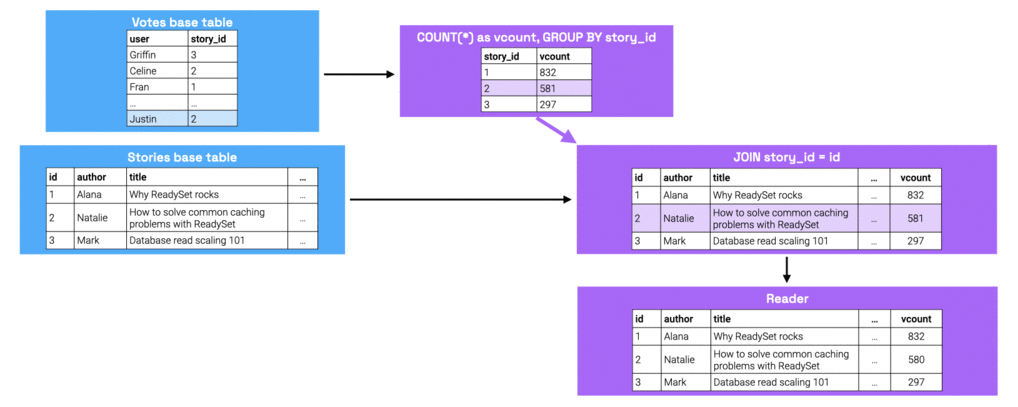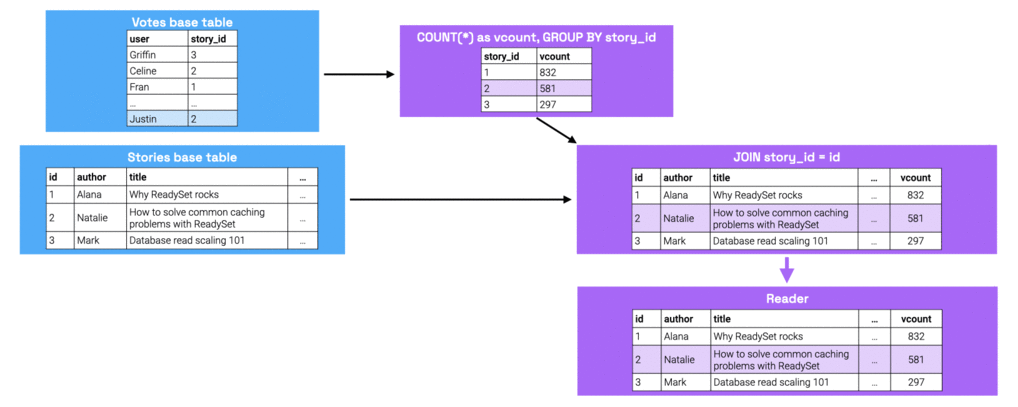
Now, we’ll take a look at what happens when the data changes. Let’s say that we add a record to the Votes table to
reflect the fact that Justin voted for the story with ID 2. This update would first be applied to the Votes base table at
the root of the graph, and then be propagated through the graph, updating all children nodes along that way.
The figure below shows the modified state at each node as the result of this write.
When performing a read (i.e., executing the prepared statement), we're essentially just doing a key-value lookup for the parameter value on the relevant column of the reader node.
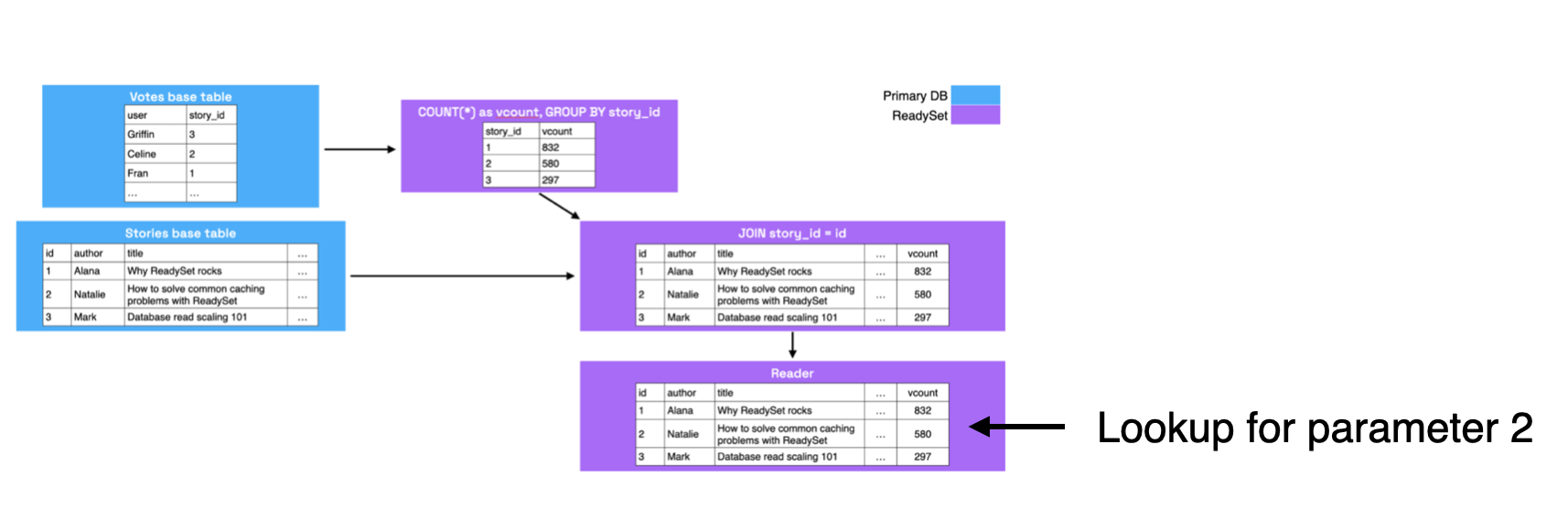
In this case, we're doing a lookup for key 2 on the ID column of the reader node. These lookups are blazingly fast, since reader
nodes are lock-free, in-memory data structures.